

تحسين تكلفة واستخدام مجموعة Databricks بدون جداول النظام
في معظم بيئات Databricks المؤسسية (مثل MSC أو النظم البيئية التحليلية الكبيرة)، قد تكون جداول النظام مثل system.job_run_logs أو system.cluster_events مقيدة أو معطلة بسبب سياسات الأمان أو الحوكمة.
ومع ذلك، فإن تتبع استخدام الكتلة والتكلفة أمر بالغ الأهمية من أجل:
- فهم مدى كفاءة استخدام المهام للحوسبة
- تحديد الكتل الخاملة أو تسرب التكاليف
- التنبؤ بميزانية البنية التحتية
- بناء لوحات معلومات التكلفة المخصصة
تعرض هذه المدونة نهجًا خطوة بخطوة لحساب استخدام الكتلة والتكلفة باستخدام Databricks REST APIs فقط — دون الحاجة إلى جداول النظام.
حالة استخدام المشروع
في منصة بيانات MSC الخاصة بنا، نقوم بتشغيل كتل Databricks متعددة عبر التطوير والاختبار والإنتاج. \n واجهنا ثلاثة تحديات رئيسية:
- عدم الوصول إلى جداول النظام (مقيدة بواسطة سياسات المسؤول)
- الكتل المؤقتة للمهام المُنشأة ديناميكيًا بواسطة ADF أو خطوط التنسيق
- لا توجد رؤية مباشرة لكيفية ترجمة استخدام الكتلة إلى تكلفة
لذلك، قمنا ببناء محلل استخدام خفيف الوزن يقوم بـ:
- استخراج البيانات من Databricks REST APIs
- حساب وقت تشغيل المهمة مقابل وقت تشغيل الكتلة
- تقدير التكلفة باستخدام معدلات DBU و VM
- إخراج DataFrame سهل الاستهلاك
المشكلة والنهج
التحدي المحدد
غالبًا ما تحتاج الفرق إلى معرفة:
- ما هي الكتل الخاملة (التي تعمل مع نشاط مهمة منخفض)؟
- ما هي نسبة الاستخدام % (وقت تشغيل المهمة مقابل وقت تشغيل الكتلة)؟
- كم تكلف كل كتلة (DBU + VM)؟
عندما تكون جداول نظام Unity Catalog (على سبيل المثال، system.job_run_logs) غير متوفرة، فإن النهج القائم على SQL الافتراضي يفشل. يصبح REST API البديل الموثوق.
النهج عالي المستوى المستخدم في الدفتر
- سرد الكتل عبر /api/2.0/clusters/list.
- تقدير وقت تشغيل الكتلة باستخدام الطوابع الزمنية داخل JSON الكتلة (الحقول created/start/terminated). (هذا هو البديل العملي عندما لا يكون /clusters/events متاحًا.)
- الحصول على تشغيلات المهام الأخيرة باستخدام /api/2.1/jobs/runs/list مع فلاتر الوقت (أو الحد).
- مطابقة تشغيلات المهام مع الكتل باستخدام cluster_instance.cluster_id (أو بيانات تعريف الكتلة الأخرى).
- حساب الاستخدام: نسبة الاستخدام % = إجمالي_وقت_تشغيل_المهمة / إجمالي_وقت_تشغيل_الكتلة.
- تقدير التكلفة باستخدام صيغة بسيطة: التكلفة = ساعات_التشغيل × (DBU/hr × DBU المفترض) + ساعات_التشغيل × العقد × VM $/hr.
يستخدم هذا الدفتر عمدًا استعلامات محدودة (آخر N عملية تشغيل، نافذة زمنية) حتى يعمل بسرعة.
\ 1. الإعداد والتكوين
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ يقوم هذا القسم بتهيئة:
- عنوان URL لمساحة العمل ورمز المصادقة
- النطاق الزمني الذي تريد تحليل الاستخدام فيه
- افتراضات التكلفة:
- معدل DBU ($/hr لكل DBU)
- تكلفة عقدة VM
- استهلاك DBU التقريبي
في إعدادات المؤسسات، يمكن جلب هذه المعدلات ديناميكيًا عبر FinOps أو واجهات برمجة تطبيقات الفوترة.
-
دالة غلاف API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ توحد هذه الدالة المساعدة جميع استدعاءات GET الخاصة بـ REST API. \n إنها:
-
تبني عنوان URL الكامل لنقطة النهاية
-
تتعامل مع 404 بسلاسة (مهم عندما تنتهي صلاحية الكتل أو التشغيلات)
-
تُرجع JSON محلل
لماذا هذا مهم: تضمن هذه الدالة تواصل API نظيف دون كسر تدفق الدفتر إذا كانت أي بيانات كتلة مفقودة.
\
-
سرد جميع الكتل النشطة
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ يستعيد هذا جميع الكتل المتاحة في مساحة العمل الخاصة بك. \n إنه يعادل عرض علامة التبويب "الحوسبة" برمجيًا. \n تحتوي الاستجابة على:
-
معرفات الكتل
-
الأسماء
-
أعداد العقد
-
معلومات المنشئ
-
أوقات الإنشاء والإنهاء
حالة الاستخدام: يساعد في تحديد الكتل التي تستهلك الموارد في النافذة المحددة.
4. تقدير وقت تشغيل الكتلة
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ نحسب إجمالي ساعات التشغيل لكل كتلة:
-
يستخدم طوابع الإنشاء والإنهاء
-
يتعامل مع الكتل التي تعمل حاليًا (terminated_time مفقود)
-
يقوم بالتطبيع إلى ساعات
لماذا هذا مهم: هذه القيمة هي المقام للاستخدام — وتمثل إجمالي وقت تشغيل الكتلة خلال النافذة.
5. الحصول على تشغيلات المهام الأخيرة
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ بدلاً من جلب سجل المهام بالكامل (وهو بطيء)، \n تسترجع هذه الدالة آخر 10 عمليات تشغيل مهام للتشخيص السريع.
في الإنتاج، يمكنك التصفية حسب:
- job_id محدد
- completed_only=true
- نافذة التاريخ (start_time_from، start_time_to)
\
-
حساب الاستخدام والتكلفة
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
هذا هو قلب المنطق:
-
يحلق عبر كل كتلة
-
يحسب إجمالي وقت تشغيل المهمة لكل كتلة (باستخدام واجهة برمجة تطبيقات تشغيل المهام)
-
يستمد نسبة الاستخدام = (ساعات_المهمة / ساعات_تشغيل_الكتلة) × 100
-
تقدير التكلفة:
- تكلفة DBU بناءً على المعدل × DBU/hr
- تكلفة VM = عدد_العقد × تكلفة_العقدة/hr × ساعات_التشغيل
لماذا هذا مهم: \n يعطي هذا صورة موحدة للكفاءة والنفقات — مفيد لتحديد الكتل ذات التكلفة العالية ولكن الاستخدام المنخفض.
7. تنسيق خط الأنابيب
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ هذه الكتلة النهائية:
-
تسترجع البيانات
-
تنفذ حساب التكلفة
-
تعرض DataFrame المرتب
عمليًا، يمكن لـ DataFrame هذا:
-
التصدير إلى Excel أو جدول Delta
-
الإرسال إلى لوحات معلومات Power BI
-
التكامل في خطوط أنابيب أتمتة FinOps
\
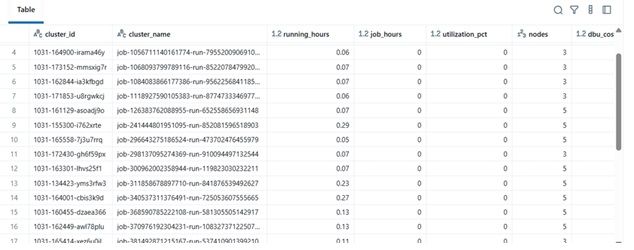
مثال على النتائج
| cluster_name | running_hours | job_hours | utilization_pct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36.5 | 28.0 | 76.7% | 4 | $142.8 | | dev-debug | 12.0 | 1.2 | 10.0% | 2 | $18.4 | | nightly-adf | 48.0 | 45.0 | 93.7% | 6 | $260.4 |
\ 
\ \
-
الفائدة في العالم الحقيقي
من خلال تنفيذ هذا المحلل:
-
يمكن لفرق الهندسة تتبع تكلفة الكتلة حتى بدون الوصول إلى التدقيق.
-
يحصل المدراء على رؤية للكتل غير المستغلة بشكل كافٍ.
-
يمكن لـ DevOps إنهاء الكتل منخفضة الاستخدام تلقائيًا.
-
يمكن للمالية التحقق من فواتير Databricks مع المقاييس الداخلية.
في مشروع MSC الخاص بنا، استخدمنا هذا كجزء من مجموعة مراقبة منصة البيانات الخاصة بنا — الجمع بين بيانات REST API وسجلات مهام ADF واتجاهات التكلفة في لوحة معلومات موحدة.
\
قد يعجبك أيضاً

ناسداك وCME يطلقان مؤشر ناسداك-CME للعملات المشفرة الجديد—تغيير جذري في الأصول الرقمية

مؤشر موسم العملات البديلة ينخفض إلى 40: إشارة كاشفة لمعنويات سوق الكريبتو
