

Optymalizacja kosztów i wykorzystania klastra Databricks bez tabel systemowych
W większości korporacyjnych środowisk Databricks (takich jak MSC lub duże ekosystemy analityczne), tabele systemowe takie jak system.jobrunlogs lub system.cluster_events mogą być ograniczone lub wyłączone ze względu na zasady bezpieczeństwa lub zarządzania.
Jednak śledzenie wykorzystania klastrów i kosztów jest kluczowe dla:
- Zrozumienia jak efektywnie zadania wykorzystują zasoby obliczeniowe
- Identyfikacji bezczynnych klastrów lub wycieków kosztów
- Prognozowania budżetu infrastruktury
- Budowania niestandardowych pulpitów kosztów
Ten blog demonstruje podejście krok po kroku do obliczania wykorzystania klastrów i kosztów używając tylko Databricks REST API — bez wymaganych tabel systemowych.
Przypadek użycia projektu
Na naszej platformie danych MSC uruchamiamy wiele klastrów Databricks w środowiskach deweloperskim, testowym i produkcyjnym. \n Mieliśmy trzy główne wyzwania:
- Brak dostępu do tabel systemowych (ograniczony przez polityki administratora)
- Efemeryczne klastry dla zadań tworzone dynamicznie przez ADF lub potoki orkiestracji
- Brak bezpośredniego wglądu w to, jak wykorzystanie klastrów przekłada się na koszty
Dlatego zbudowaliśmy lekki analizator wykorzystania, który:
- Pobiera dane z Databricks REST API
- Oblicza czas działania zadań w porównaniu do czasu działania klastra
- Szacuje koszty używając stawek DBU i VM
- Wyprowadza łatwy do wykorzystania DataFrame
Problem i podejście
Zidentyfikowane wyzwanie
Zespoły często muszą wiedzieć:
- Które klastry są bezczynne (działają z niską aktywnością zadań)?
- Jaki jest procent wykorzystania (czas działania zadań vs czas pracy klastra)?
- Ile kosztuje każdy klaster (DBU + VM)?
Gdy tabele systemowe Unity Catalog (np. system.jobrunlogs) są niedostępne, domyślne podejście oparte na SQL zawodzi. REST API staje się niezawodnym rozwiązaniem zastępczym.
Wysokopoziomowe podejście używane w notatniku
- Listowanie klastrów poprzez /api/2.0/clusters/list.
- Szacowanie czasu pracy klastra używając znaczników czasu wewnątrz JSON klastra (pola created/start/terminated). (To jest pragmatyczne rozwiązanie zastępcze, gdy /clusters/events jest niedostępne.)
- Pobieranie ostatnich uruchomień zadań używając /api/2.1/jobs/runs/list z filtrami czasowymi (lub limitem).
- Dopasowanie uruchomień zadań do klastrów używając clusterinstance.clusterid (lub innych metadanych klastra).
- Obliczanie wykorzystania: procent wykorzystania = totaljobruntime / totalclusteruptime.
- Szacowanie kosztów używając prostego wzoru: koszt = runninghours × (DBU/hr × assumed DBU) + runninghours × nodes × VM $/hr.
Ten notatnik celowo używa ograniczonych zapytań (ostatnie N uruchomień, okno czasowe), aby działał szybko.
\ 1. Konfiguracja i ustawienia
# Databricks Cluster Utilization & Cost Analyzer (no system tables) # Author: GPT-5 | Works on any workspace with REST API access # Requirements: Databricks Personal Access Token, Workspace URL # You can run this inside a Databricks notebook or externally. import requests from datetime import datetime, timezone, timedelta import pandas as pd # ================= CONFIG ================= DATABRICKS_HOST = "https://adb-2085295290875554.14.azuredatabricks.net/" # Replace with your workspace URL # DATABRICKS_TOKEN = "" # Replace with your PAT HEADERS = {"Authorization": f"Bearer {token}"} params={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} # Time window (e.g., last 7 days) DAYS_BACK = 7 SINCE_TS_MS = int((datetime.now(timezone.utc) - timedelta(days=DAYS_BACK)).timestamp() * 1000) UNTIL_TS_MS = int(datetime.now(timezone.utc).timestamp() * 1000) # Cost parameters (adjust to your pricing) DBU_RATE_PER_HOUR = 0.40 # $ per DBU/hr VM_COST_PER_NODE_PER_HOUR = 0.60 # $ per cloud VM node/hr DEFAULT_DBU_PER_CLUSTER_PER_HOUR = 8 # Typical for small-medium jobs cluster # ==========================================
\ Ta sekcja inicjalizuje:
- URL przestrzeni roboczej i token do uwierzytelniania
- Zakres czasowy, dla którego chcesz analizować wykorzystanie
- Założenia kosztowe:
- Stawka DBU ($/hr za DBU)
- Koszt węzła VM
- Przybliżone zużycie DBU
W konfiguracjach korporacyjnych te stawki mogą być pobierane dynamicznie przez Twoje API FinOps lub rozliczeniowe.
-
Funkcja opakowująca API
\
# Api GET request def api_get(path, params=None): url = f"{DATABRICKS_HOST.rstrip('/')}{path}" try: r = requests.get(url, headers=HEADERS, params=params, timeout=60) if r.status_code == 404: print(f"Skipping :{path} (404 Not Found)") return {} r.raise_for_status() return r.json() except Exception as e: print(f"Error: {e}") return {}
\ Ta funkcja pomocnicza standaryzuje wszystkie wywołania REST API GET. \n Ona:
-
Buduje pełny URL punktu końcowego
-
Obsługuje błąd 404 w sposób elegancki (ważne gdy klastry lub uruchomienia wygasły)
-
Zwraca sparsowany JSON
Dlaczego to ma znaczenie: Ta funkcja zapewnia czystą komunikację API bez przerywania przepływu notatnika, jeśli jakiekolwiek dane klastra brakują.
\
-
Listowanie wszystkich aktywnych klastrów
\
# ---------- STEP 1: Get All Clusters Related Details ---------- def list_clusters(): clusters = [] res = api_get("/api/2.0/clusters/list") return res.get("clusters", [])
\ To pobiera wszystkie klastry dostępne w Twojej przestrzeni roboczej. \n Jest to równoważne z przeglądaniem zakładki "Compute" programowo. \n Odpowiedź zawiera:
-
Identyfikatory klastrów
-
Nazwy
-
Liczby węzłów
-
Informacje o twórcy
-
Czasy utworzenia i zakończenia
Przypadek użycia: Pomaga zidentyfikować które klastry zużywają zasoby w wybranym oknie czasowym.
4. Szacowanie czasu działania klastra
\
# ---------- STEP 2: Get Cluster Events Runtime ---------- def get_cluster_runtime(cluster): events = [] offset = 0 limit = 200 # while True: # params = {"cluster_id": cluster_id} created = cluster.get("creator_user_name") created_time = cluster.get("start_time") or cluster.get("created_time") terminated_time = cluster.get("terminated_time") if not created_time: return 0 end_ts = terminated_time or UNTIL_TS_MS start_ms = max(created_time, SINCE_TS_MS) runtime_ms = max(0, end_ts - start_ms) return runtime_ms /1000/3600
\ Obliczamy łączne godziny działania dla każdego klastra:
-
Używa znaczników czasu utworzenia i zakończenia
-
Obsługuje aktualnie działające klastry (brak terminated_time)
-
Normalizuje do godzin
Dlaczego to jest ważne: Ta wartość jest mianownikiem dla wykorzystania — reprezentując całkowity czas pracy klastra podczas okna czasowego.
5. Pobieranie ostatnich uruchomień zadań
\
# ------------------Get Recent Job Runs ---------------------------- def get_recent_job_runs(): params ={"start_time":int(datetime.now().timestamp()*1000),"end_time":int((datetime.now()+timedelta(days=1)).timestamp()*1000),"order":"DESCENDING"} res = api_get("/api/2.1/jobs/runs/list", params) return res.get("runs", [])
\ Zamiast pobierać całą historię zadań (co jest wolne), \n Ta funkcja pobiera 10 ostatnich uruchomień zadań dla szybkiej diagnostyki.
W produkcji możesz filtrować według:
- Konkretnego job_id
- completed_only=true
- Okna daty (starttimefrom, starttimeto)
\
-
Obliczanie wykorzystania i kosztów
\
# -------------------------------------Compute Cost and parse cluster utilization detials --------------------- def compute_utilization_and_cost(clusters, job_runs): records =[] now_ms = int(datetime.now(timezone.utc).timestamp() * 1000) for c in clusters: cid = c.get("cluster_id") cname = c.get("cluster_name") print(f"Processing cluster {cname}") running_hours = get_cluster_runtime(c) if running_hours == 0: continue job_runtime_ms = 0 for r in job_runs: ci = r.get("cluster_instance",{}) if ci.get("cluster_id") == cid: s = r.get("start_time") or SINCE_TS_MS e = r.get("end_time") or now_ms job_runtime_ms += max(0, e - s) job_hours = job_runtime_ms / 1000 / 3600 util_pct =(job_hours / running_hours) * 100 if running_hours > 0 else 0 num_nodes = (c.get("num_workers") or c.get("autoscale",{}).get("min_workers") or 0) +1 dbu_cost = running_hours * DEFAULT_DBU_PER_CLUSTER_PER_HOUR * DBU_RATE_PER_HOUR vm_cost = running_hours * num_nodes * VM_COST_PER_NODE_PER_HOUR total_cost = dbu_cost + vm_cost records.append({ "cluster_id": cid, "cluster_name": cname,"running_hours":round(running_hours,2), "job_hours": round(job_hours,2) ,"utilization_pct": round(util_pct,2), "nodes": num_nodes,"dbu_cost": round(dbu_cost,2), "vm_cost": round(vm_cost,2), "total_cost": round(total_cost,2) }) return pd.DataFrame(records)
To jest serce logiki:
-
Iteruje przez każdy klaster
-
Oblicza łączny czas działania zadań na klaster (używając API uruchomień zadań)
-
Wyprowadza procent wykorzystania = (jobhours / clusterrunning_hours) × 100
-
Szacuje koszty:
- Koszt DBU na podstawie stawki × DBU/hr
- Koszt VM = nodecount × nodecost/hr × running_hours
Dlaczego to ma znaczenie: \n To daje zunifikowany obraz efektywności i wydatków — przydatny do identyfikacji klastrów o wysokich kosztach, ale niskim wykorzystaniu.
7. Orkiestracja potoku
\
# ---------- MAIN ---------- print(f"Collecting data for last {DAYS_BACK} days...") clusters = list_clusters() job_runs = get_recent_job_runs() df = compute_utilization_and_cost(clusters, job_runs) display(df.sort_values("utilization_pct", ascending=False))
\ Ten końcowy blok:
-
Pobiera dane
-
Wykonuje obliczenia kosztów
-
Wyświetla posortowany DataFrame
W praktyce ten DataFrame może być:
-
Eksportowany do Excela lub tabeli Delta
-
Wysłany do pulpitów Power BI
-
Zintegrowany z potokami automatyzacji FinOps
\
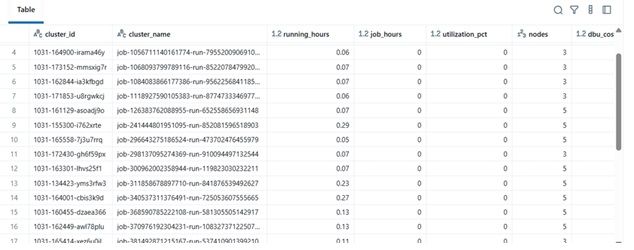
Przykład wyników
| clustername | runninghours | jobhours | utilizationpct | nodes | total_cost | |----|----|----|----|----|----| | etl-job-prod | 36,5 | 28,0 | 76,7% | 4 | $142,8 | | dev-debug | 12,0 | 1,2 | 10,0% | 2 | $18,4 | | nightly-adf | 48,0 | 45,0 | 93,7% | 6 | $260,4 |
\ 
\ \
-
Korzyści w rzeczywistym świecie
Wdrażając ten analizator:
-
Zespoły inżynieryjne mogą śledzić koszty klastrów nawet bez dostępu do audytu.
-
Menedżerowie uzyskują wgląd w niedostatecznie wykorzystane klastry.
-
DevOps może automatycznie kończyć klastry o niskim wykorzystaniu.
-
Finanse mogą walidować faktury Databricks z wewnętrznymi metrykami.
W naszym projekcie MSC użyliśmy tego jako części naszego stosu obserwowalności platformy danych — łącząc dane REST API, logi zadań ADF i trendy kosztowe w zunifikowany pulpit.
\
Możesz także polubić

Nasdaq i CME uruchamiają nowy indeks Nasdaq-CME Crypto Index — przełom w świecie aktywów cyfrowych

Indeks Sezonu Altcoinów Spada do 40: Znaczący Sygnał dla Nastrojów na Rynku Kryptowalut
